Debt to Equity : Total debt of the company upon funds for equity share holders. The ratio should be less than 0.25 Debt to equity < 0.25
Return on capital employed : EBIT/Annual Average Capital Employed EBIT : Earning Before Interest and Taxes Capital Employed = Share capital + Reserves + Borrowings It should be greater than > 20%
Return on capital employed > 20%
Net Profit : Net profit of the company during last 12 months It should be greater than 200 Crores
Net Profit > 200
Public Holding : Public shareholding excluding FII, DII and Government holding as per latest shareholding filing. Public Holding < 30%
Pledged Percentage : Percentage of promoter holding pledge. Promoter is the higher official of the company. Pledged Percentage < 10%
PE Ratio: Price to Earnings Ratio – is the ratio of price of the share relative to its Earnings per share (EPS) Price to Earning < Industry PE
Screener Query
Debt to equity < 0.25 AND Return on capital employed > 20% AND Net Profit > 200 AND Public Holding < 30% AND Pledged Percentage < 10% AND Price to Earning < Industry PE
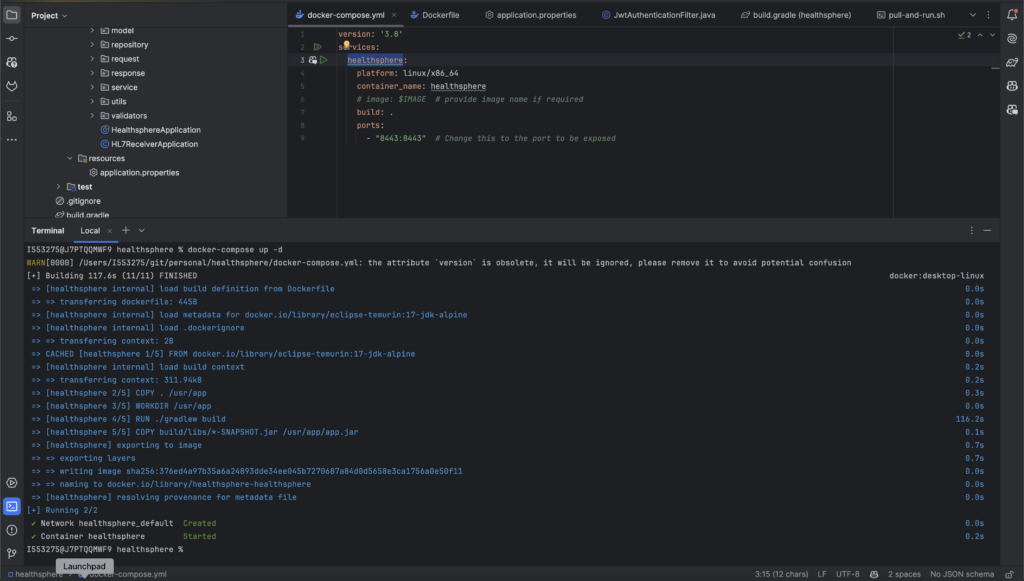
There are many ways in which we can containerize a java application. In this tutorail we will build the java application with gradlew (gradle wrapper) inside the docker and the created image is then stored in your local docker image repo. Which can be viewed by the command docker image ls
The base image for this image would be eclipse-temurin:17-jdk-alpine, assuming that the project uses jdk-17 for building. Here we copy all the files in the present directory to a folder inside the container (ie, to /usr/app). A gradlew build is run on the files, which generates jar file in the format – build/libs/*-SNAPSHOT.jar If your application creates a jar file with a different naming convention, the corresponding change must be done here. The COPY build/libs/*-SNAPSHOT.jar $APP_HOME/$JAR_NAME command copies and renames the jar to the working directory. New jar file will be /usr/app/app.jar
The container exposes 8443 port, this port must be the same as that of the application port. The last line depicts the command which runs the java application.
Creating the docker-compose file
docker-compose.yml
version: '3.8'
services:
healthsphere:
platform: linux/x86_64
container_name: healthspherebuild: .
ports:
- "8443:8443" # Change this to the port to be exposed
Next step is to create a docker-compose file. So that it will be easy for us to start and stop the docker container.
Docker-compose explanation
The services section describes which are services/containers are to be started on the docker-compose up command
Here my container name and service name is same – ie “healthsphere”, you can use any name of your choice.
platform: linux/x86_64 may be not be required, unless you are running it on a mac device with m3 chip.
build: . ### builds the Dockerfile present in the same folder. The Dockerfile and docker-compose.yml should be in the same folder fo this to work
ports: ### section specifies the inner and outer port to be exposes. With the left hand side port being the inner container/image port and right hand side being the exposed port. Here I have configured both the inner and outer(exposed) port to be 8443. You can configure the exposed port to be something else. For example- it can also look lilke this ports: – “8080:8443”
This means the application running inside the container is running at port 8443 – this should be same as the exposed port in Dockerfile and 8080 is the exposed port of the container, which is visible to the outside world.
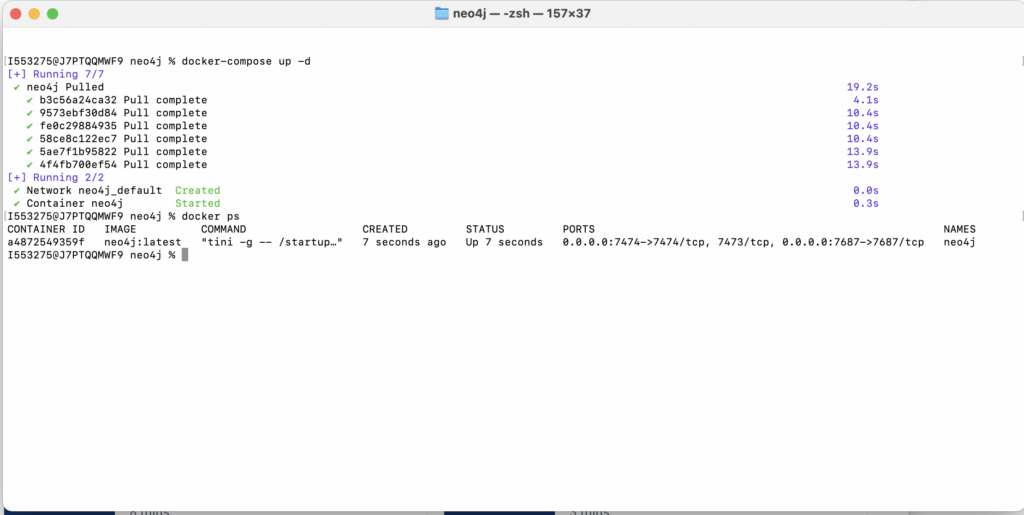
Running the application
docker-compose up -d
The above command build the Dockerfile, and starts the application in the container.
Each line in Dockerfile will be executed one by one and we will be able to see the execution in the logs that is getting printed.
The container would be started and would be serving at port 8443, which can be viewed by the docker ps command
Conclusion
Hence we learned to how to containerize a java springboot application. If you need any help, feel free to comment in the comment section.
GraphDB or Knowledge Graph uses Graph like structure to represent data. Each data element in a graphDB is represented by a Node. In this section we will be exploring how semantic search is carried for nodes in Neo4j Graph database.
This section assumes that
Your Neo4j instance is up and running
You have loaded your Neo4j with some data
Added embeddings field to each node where you have to perform a similarity search
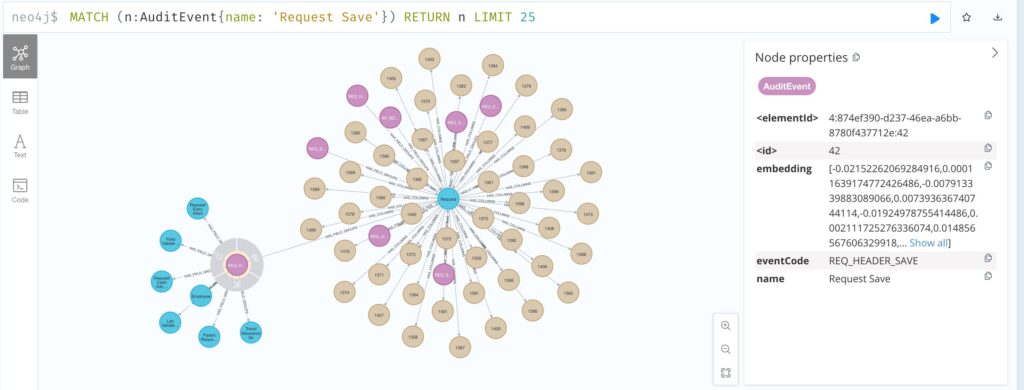
Lets assume We have following relationship in our graph database. (auditEvent:AuditEvent)-[:HAS_FIELD_GROUPS]->(fieldGroup:FieldGroup)
Inorder to do a semantic search over fieldGroup for a particular auditEvent. The below given cypher would return all the nodes of fieldGroups which satisfies the condition.
Here we are using cosine similarity search to find the most similar nodes.
from langchain_community.graphs import Neo4jGraph
cypher = '''
MATCH (auditEvent:AuditEvent{ eventCode: $eventCode })-[:HAS_FIELD_GROUPS]->(fieldGroup:FieldGroup)
WITH auditEvent,fieldGroup,
vector.similarity.cosine(fieldGroup.embedding, $embedding) AS score WHERE score > 0.8
RETURN fieldGroup.fgCode, fieldGroup.name, score order by score desc limit 1
'''
#where objEmbedding is the embeddings data
objects = findObject('Request Save', objEmbedding)
print(objects)
The variable $eventCode and $embedding must be provided at the runtime.
The python code to return the nodes would like this :